

我们知道爬虫的比较常见的应用都是应用在数据分析上,爬虫作为数据分析的前驱,它负责数据的收集。今天我们以python爬取二手房数据为例来进行一个python爬虫实战。(内附python爬虫源代码)
一、查找数据所在位置:
打开链家官网,进入二手房页面,选取某个城市,可以看到该城市房源总数以及房源列表数据。
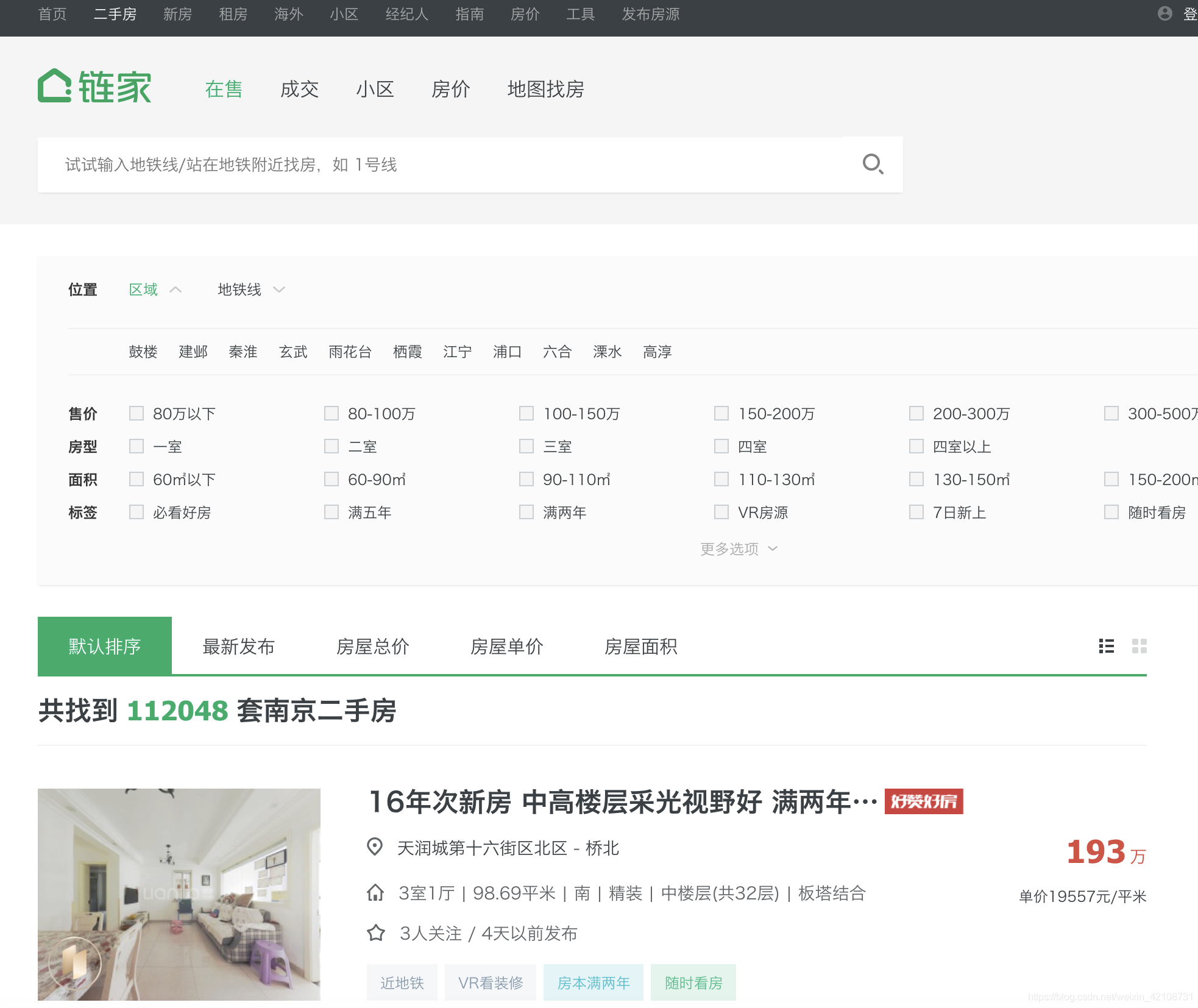
二、确定数据存放位置:
某些网站的数据是存放在html中,而有些却api接口,甚至有些加密在js中,还好链家的房源数据是存放到html中:

三、获取html数据:
通过requests请求页面,获取每页的html数据
# 爬取的url,默认爬取的南京的链家房产信息
url = 'https://nj.***.com/ershoufang/pg{}/'.format(page)
# 请求url
resp = requests.get(url, headers=headers, timeout=10)代码中的网站非真真实网址,不可直接运行!
四、解析html,提取有用数据:
通过BeautifulSoup解析html,并提取相应有用的数据
soup = BeautifulSoup(resp.content, 'lxml')
# 筛选全部的li标签
sellListContent = soup.select('.sellListContent li.LOGCLICKDATA')
# 循环遍历
for sell in sellListContent:
# 标题
title = sell.select('div.title a')[0].string
# 先抓取全部的div信息,再针对每一条进行提取
houseInfo = list(sell.select('div.houseInfo')[0].stripped_strings)
# 楼盘名字
loupan = houseInfo[0]
# 对楼盘的信息进行分割
info = houseInfo[0].split('|')
# 房子类型
house_type = info[1].strip()
# 面积大小
area = info[2].strip()
# 房间朝向
toward = info[3].strip()
# 装修类型
renovation = info[4].strip()
# 房屋地址
positionInfo = ''.join(list(sell.select('div.positionInfo')[0].stripped_strings))
# 房屋总价
totalPrice = ''.join(list(sell.select('div.totalPrice')[0].stripped_strings))
# 房屋单价
unitPrice = list(sell.select('div.unitPrice')[0].stripped_strings)[0]小结
以上就是python爬取二手房数据的详细内容,更多python爬虫实战教程请关注W3Cschool其它相关文章!









 浙公网安备33010502006705号
浙公网安备33010502006705号